从高中的时候就开始写微博了。
那个时候的自己总是天马行空的乱想一气,想完了就想着把自己刚刚的这些想法保存下来。配合着那个时候新买的“入门款”智能机5233兴奋的不得了, 再加上断网事件已经过去,可以登陆互联网了,所以便“执机”记录,一直持续到现在。截止到目前已经有1000多条记录了。由于近几年不太看好微博的发展,以及也想把自己的数据全部搜集起来,于是便有了这个项目。
一、前期调研
1.技术选择
搜了一下最近关于新浪微博爬虫的信息,没有信息。嗯,但是前段时间github有一个python新浪微博爬虫和一个php爬虫的项目挺火的,这两个可以借鉴一下。考虑到我拿手的是php,和时间成本问题,所以就选择php爬虫了。
2.辅助工具
fiddler(抓包工具),chrome(网站分析),sublime text。
二、微博分析
1.抓取站点研究
新浪微博目前有两种形式,一种是桌面端,它是服务器渲染的页面,需要爬取页面后再分析研究html结构来提取数据,比较麻烦,不太推荐。另外一种是移动端,json形式的前后天数据交互,可以更加方便快捷的解析数据,推荐使用。移动端的地址:m.weibo.cn
2.url研究
登陆 m.weibo.cn 后,F12查看xhr实际地址:
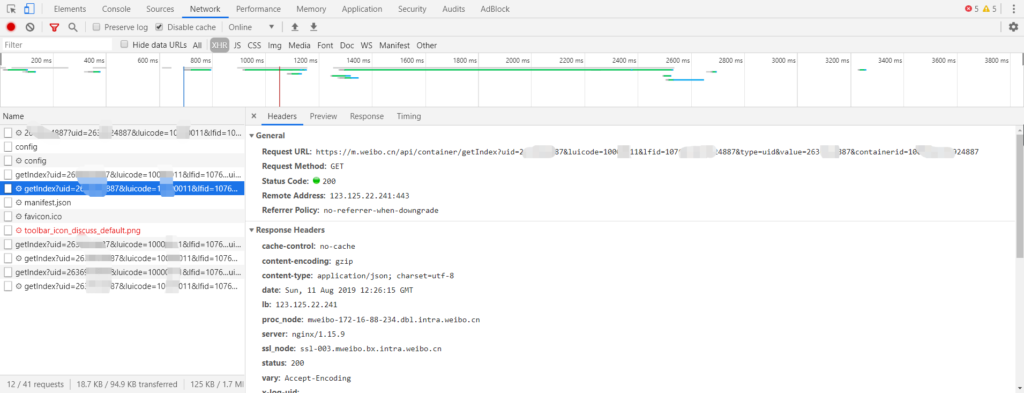
由于移动版没有翻页,是滑动刷新的,所以还要研究一下这个xhr,对比一下。
经过对比两个url发现如下规律:
https://m.weibo.cn/api/container/getIndex?uid=固定参数1&luicode=固定参数2&lfid=固定参数三&type=uid&value=固定参数四&containerid=固定参数五&page=变量页数3.测试
- 加上cookie,进行测试上面所拼接的url是否能获取期望中的数据,并对该数据进行json解析
- 测试寻找边界,在page超过实际数目的情况下,会返回 {“ok”:0,”msg”:”这里还没有内容”,”data”:{“cards”:[]}}
- 测试间隔为300ms,在测试到第 56 页的时候,返回 http:418 I’m a teapot(我是一个茶壶),哈哈哈哈哈哈哈。
三、抓取
四、总结
虽然最后完成了主要的需求,但是还有些不完美的地方
- 尝试配合使用代理和多线程,应该可以抓取速度更快。
- 目前只抓取了文字,图片还没有进行抓取
- 登陆这一块刨去直接使用cookie的方式,试试代理登陆的方式。
- 对代码应该进行抽象封装,以后可以快速抓取别的网站。
收获
- sleep 和 usleep
我对流沙说,让风把我吹走吧。
流沙说,你没了根,马上就死。
于是我毅然往上一挣扎,其实也没有费力。我离开了流沙,往脚底一看,操,原来我不是一棵植物,我是一只动物,这帮孙子骗了我二十多年。
—— 韩寒《1988》